데이콘 - 영화 관객수 예측 모델 개발에서 사용하는 데이터를 가지고 모델을 만들었다. 데이터에 대한 자세한 설명은 다음의 링크를 확인하면 된다. 데이터 설명
[문화] 영화 관객수 예측 모델 개발
출처 : DACON - Data Science Competition
dacon.io
우선 모델을 만들기 위해 필요한 패키지들을 import 해준다.
import pandas as pd
import lightgbm as lgb
import seaborn as sns
%matplotlib inline
위에서 %%matplotlib inline은 seaborn을 통해 그래프를 그렸을 때 그래프가 나오지 않을 때 작성하는 코드이다.
train = pd.read_csv('./data/movies_train.csv')
test = pd.read_csv('./data/movies_test.csv')
submission = pd.read_csv('./data/submission.csv')
다음으로는 train과 test, submission 파일을 읽어온다. train 데이터는 말 그대로 모델 학습을 위한 데이터이다. test 데이터는 train 데이터와는 다르게 관객수가 없고, train 데이터와 다르다. submission 데이터는 제출을 위한 품을 제공하는 데이터로 test 데이터와 index가 같다.
print(train.tail())
title distributor genre release_time time screening_rat director \
595 해무 (주)NEW 4 2014-08-13 111 청소년 관람불가 심성보
596 파파로티 (주)쇼박스 4 2013-03-14 127 15세 관람가 윤종찬
597 살인의 강 (주)마운틴픽쳐스 1 2010-09-30 99 청소년 관람불가 김대현
598 악의 연대기 CJ 엔터테인먼트 2 2015-05-14 102 15세 관람가 백운학
599 베를린 CJ 엔터테인먼트 10 2013-01-30 120 15세 관람가 류승완
dir_prev_bfnum dir_prev_num num_staff num_actor box_off_num
595 3833.0 1 510 7 1475091
596 496061.0 1 286 6 1716438
597 0.0 0 123 4 2475
598 0.0 0 431 4 2192525
599 0.0 0 363 5 7166532
위의 코드는 train 데이터의 마지막 row에서 위로 5개의 데이터만 보여준 것이다. 비슷한 함수로 head()가 있지만 tail() 함수를 사용하면 데이터의 총개수도 같이 파악할 수 있어서 tail()을 더 많이 사용한다.
print(test.tail())
title distributor genre release_time time screening_rat \
238 해에게서 소년에게 디씨드 4 2015-11-19 78 15세 관람가
239 울보 권투부 인디스토리 3 2015-10-29 86 12세 관람가
240 어떤살인 (주)컨텐츠온미디어 2 2015-10-28 107 청소년 관람불가
241 말하지 못한 비밀 (주)씨타마운틴픽쳐스 4 2015-10-22 102 청소년 관람불가
242 조선안방 스캔들-칠거지악 2 (주) 케이알씨지 5 2015-10-22 76 청소년 관람불가
director dir_prev_bfnum dir_prev_num num_staff num_actor
238 안슬기 2590.0 1 4 4
239 이일하 0.0 0 18 2
240 안용훈 0.0 0 224 4
241 송동윤 50699.0 1 68 7
242 이전 0.0 0 10 4
위의 코드를 통해서 test 데이터와 train 데이터의 차이를 알 수 있다.
print(submission.tail())
title box_off_num
238 해에게서 소년에게 0
239 울보 권투부 0
240 어떤살인 0
241 말하지 못한 비밀 0
242 조선안방 스캔들-칠거지악 2 0
submission 데이터는 관객수만을 저장할 수 있게 되어있다.
print(train.shape)
print(test.shape)
print(submission.shape)
(600, 12)
(243, 11)
(243, 2)
shape를 사용하여 각 데이터의 column과 row 수를 알 수 있다. test와 submission의 row값이 같은 거를 확인할 수 있다.
pd.options.display.float_format = '{:.1f}'.format
print(train[['genre', 'box_off_num']].groupby('genre').mean().sort_values('box_off_num'))
box_off_num
genre
뮤지컬 6627.0
다큐멘터리 67172.3
서스펜스 82611.0
애니메이션 181926.7
멜로/로맨스 425968.0
미스터리 527548.2
공포 590832.5
드라마 625689.8
코미디 1193914.0
SF 1788345.7
액션 2203974.1
느와르 2263695.1
train 데이터에서 장르와 관객수를 선택하고 장르별 관객수를 더해서 나타내준 것이다. 해당 코드를 통해서 느아르, 액션, SF가 인기 있는 영화 장르이고, 뮤지컬, 다큐멘터리, 서스펜스가 상대적으로 인기가 없는 영화 장르라는 것을 알 수 있다.
sns.heatmap(train.corr(), annot=True)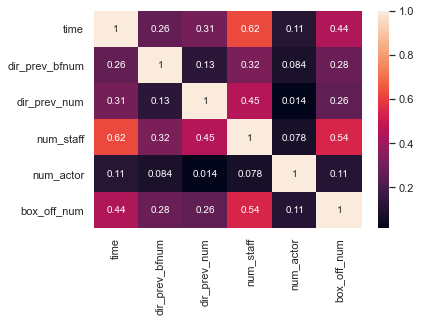
corr() 함수를 사용하여 각 데이터들의 상관계수를 알아본다. 관객수를 예측하기 위해서 box_off_num에 주목하여 그림을 살펴보면 time과 num_staff가 영향을 주는 데이터라는 것을 알 수 있다.
train.isna().sum()
title 0
distributor 0
genre 0
release_time 0
time 0
screening_rat 0
director 0
dir_prev_bfnum 330
dir_prev_num 0
num_staff 0
num_actor 0
box_off_num 0
dtype: int64
train 데이터에서 NaN값이 있는지 확인해본다.
train['dir_prev_bfnum'].fillna(0, inplace=True)
test['dir_prev_bfnum'].fillna(0, inplace=True)
train과 test 데이터의 'dir_prev_bfnum' column의 NaN값을 0으로 바꿔준다.
이렇게 영화 관객수 예측을 위한 데이터 전처리, 정보에 대해서 알아보았다.
'Artificial Intelligence > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 영화 관객수 예측 모델 (5) (0) | 2021.02.24 |
|---|---|
| [Machine Learning] 영화 관객수 예측 모델 (4) (0) | 2021.02.23 |
| [Machine Learning] 영화 관객수 예측 모델 (3) (0) | 2021.02.19 |
| [Machine Learning] 영화 관객수 예측 모델 (2) (0) | 2021.02.18 |
| [Machine Learning] 캐글 경마 데이터 선형회귀 분석 (0) | 2021.02.12 |
